Models — Selection, Dimensions, and Tradeoffs
The model inside your agent is not a detail. It determines what your agent can reason about, what it costs, and how far you are from having to rebuild everything.
The Engine Inside
You have decided to build an autonomous agent. You understand the architecture. You know what SOUL.md does, what the heartbeat is for, how skills work. Now comes the decision that most builders treat as a detail — and then regret six months later: what model do you put inside?
The model is the reasoning engine. Everything else in your agent — the skills, the memory, the ReAct loop — exists to give that engine the right context at the right time and then act on what it produces. If the engine cannot reason well enough for your task, the rest of the architecture is irrelevant. If the engine is too expensive to run continuously, your economics break. If the engine sends your data to the wrong place, your compliance does too.
OpenClaw began with Claude as its default. Peter Steinberger designed it to be model-agnostic from the start — the agent is the orchestration layer, the model is the reasoning engine that can be swapped. That design decision is the right one. This chapter gives you a framework for making that swap deliberately rather than by accident.
The Fundamental Divide
Before anything else, there is one distinction that shapes every other decision:
Closed-source models — Claude, GPT, Gemini — are the most capable reasoning engines available today. You access them through an API. You do not own them, host them, or control where your data goes.
Open-weight models — Llama, Mistral, Qwen, DeepSeek — you can download, run yourself, and keep behind your own firewall. They are generally less capable than frontier models, but the gap is narrowing fast.
| Closed-source | Open-weight | |
|---|---|---|
| Capability | Highest available | Strong and improving |
| Data control | Leaves your infrastructure | Stays wherever you run it |
| Cost model | Per token — scales with use | Fixed infrastructure cost |
| Compliance | Depends on provider | Full control |
| Iteration | Automatic upgrades | You manage upgrades |
Most serious production systems end up using both. Frontier models for complex reasoning, open-weight for high-volume or sensitive tasks. The question is knowing when each one is the right call.
June 2026 added a third reason to run both — continuity. A US export-control directive forced Anthropic to disable Fable 5 and Mythos 5 for all customers overnight; days later, OpenAI limited its newest release to government-approved partners; by June 30 access was restored. Eighteen days in which frontier-model access was a policy variable, not an engineering one. A system with an open-weight fallback behind its own firewall kept operating through all of it. Model-agnosticism is no longer just an escape hatch from pricing and deprecation — it is what keeps the heartbeat running when the API layer becomes geopolitics.
Where Your Data Goes
The model selection decision is inseparable from a data question: who sees what your agent processes?
An autonomous agent doesn’t just answer questions. It reads documents, processes customer data, reasons about financials, writes emails. Every piece of that data travels through the model’s inference layer. If that layer is outside your control, so is your data.
Think of it as a spectrum:
Full control ←────────────────────────────→ No control
Your GPU Partner GPU Cloud API Unknown
on-prem on-prem (Anthropic) provider
100% yours Shared trust Provider's No visibilityFor personal agents handling non-sensitive data, cloud APIs are fine. For business agents touching customer records, you need to understand the data processing agreement. For regulated industries — healthcare, finance, legal, government — there is no choice: data cannot leave your security perimeter.
This is not paranoia. It is a structural constraint. The only way to have certainty about data handling is to control where inference runs.
What the Model Must Be Able to Do
Before choosing which model, it helps to understand the floor — the minimum a model must clear before your architecture can function at all.
When a model falls short of this floor, the failure mode is subtle: the agent doesn’t break, it defaults. It picks the most generic path available, ignores mission structure, and produces output that looks reasonable but misses the intent. This is harder to diagnose than an error.
The four minimum denominators for agentic work:
| Minimum | Effect of failure |
|---|---|
| Tool calling reliability | Agent reasons correctly but cannot act |
| Instruction following at depth | Agent defaults to generic behavior |
| Context coherence across loops | Compounding errors, hard to trace |
| Context window ≥ 32K | Memory overflow, context loss mid-task |
Two of these deserve special attention.
Tool calling is not optional in an agentic system — it is the mechanism through which everything happens. Some models handle this reliably across hundreds of iterations. Others degrade under load, especially smaller models when tools are present. A documented quirk in Qwen3.5-27B shows that the model’s reasoning depth drops dramatically when tools are included in the request — a trained behavior, not a prompt-configuration issue. It can still do excellent work, but you need to know this before deploying it as the core of an agentic loop. (source: Appendix E — Model Evaluation)
Instruction following behaves differently across model sizes. Frontier models tolerate loose, multi-step instructions and fill gaps through reasoning. Smaller models require tighter, more atomic instructions — fewer assumptions, shorter chains, less ambiguity. This is not a dealbreaker. Once you design to the constraint, you often find the tighter instructions improve the agent even when you later switch to a larger model. It is a discipline worth developing.
The Dimensions That Actually Matter
Once a model clears the floor, evaluate it across these six dimensions:
1. Reasoning depth — Can it maintain coherent multi-step chains? Does it show its reasoning or jump to conclusions? This is hard to measure from benchmarks (more on that shortly), but easy to observe by running it on your actual task.
2. Tool use quality — Not just whether it supports function calling, but whether it selects the right tool, passes parameters correctly, and handles errors gracefully across a long loop.
3. Context window — Agentic systems inject memory, skill metadata, and conversation history into every call. Below 32K tokens you will hit the ceiling regularly. 128K+ is where agentic systems thrive.
4. Speed — When your agent loops 6–8 times per operation, latency compounds. A 6-iteration ReAct loop that takes 3 seconds in the cloud takes 300ms locally. That difference changes the user experience from “slow” to “responsive.”
5. Cost — Agents consume far more tokens than chatbots. A single agentic operation with memory injection and tool calls runs 5,000–20,000 tokens. At Claude pricing, 100 daily operations costs roughly $900/month. At Llama pricing, $30. The model choice is a cost architecture decision.
6. License — Often overlooked. Proprietary models (Claude, GPT) are API-only. Open-weight models vary: Llama carries a usage limit above 700M monthly active users, Mistral variants use Apache 2.0 with no commercial restrictions. Check before you build a business on it.
The Benchmark Problem
Every major model release comes with a chart showing it outperforms competitors. These charts are produced by the same organizations releasing the model.
This is not a reliable basis for model selection.
The problems are structural: standard benchmarks measure well-defined academic tasks optimized for comparability, not agentic performance in production. Models are sometimes trained specifically to score well on known benchmarks. The same model can score 2.7% or 28.3% on SWE-bench depending on which evaluation scaffold is used — not because the model changed, but because the test setup did. (source: Appendix E — Model Evaluation)
The Llama 4 episode in April 2025 made this concrete: Meta submitted a different model to the public leaderboard than the one they released. The gap between benchmark conditions and production conditions is a documented, recurring problem across the industry.
A subtler version of the same problem shows up in how benchmarks are presented. Look at the chart below:
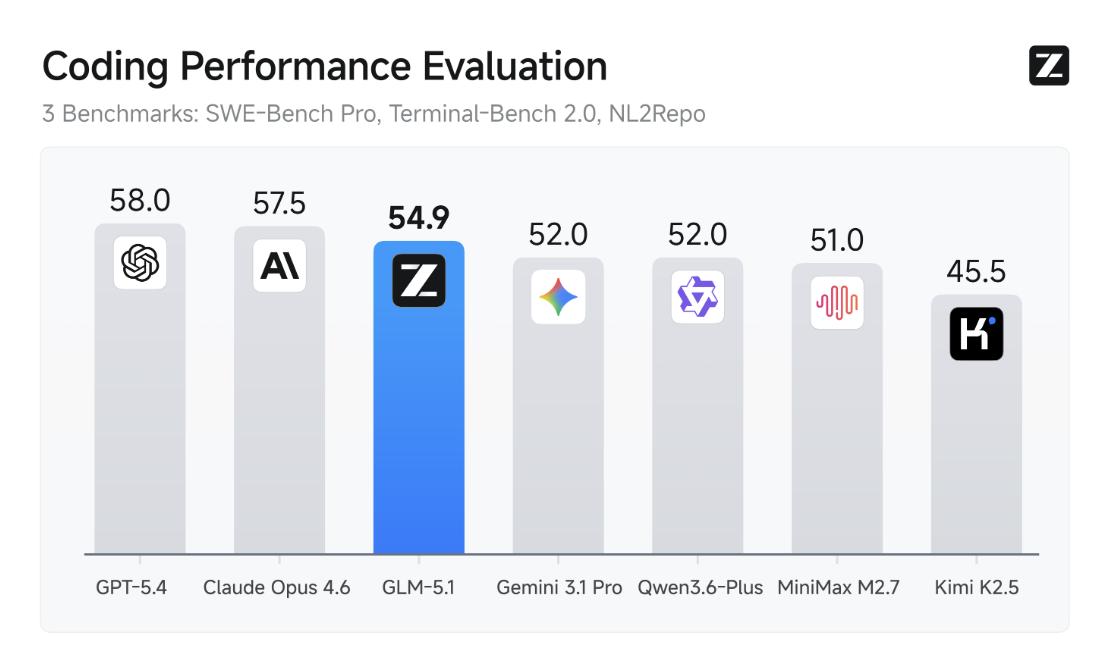 The chart was produced by Zhipu AI — the same company behind GLM-5.1, the blue bar. The color choice is not neutral: all competitors are grey, the producer’s own model is highlighted. GPT-5.4 leads at 58.0; GLM-5.1 sits at 54.9. All seven models fall within a 12.5-point range. Whether that gap matters for your agent depends entirely on what your agent does — and that is exactly what this chart cannot tell you.
The chart was produced by Zhipu AI — the same company behind GLM-5.1, the blue bar. The color choice is not neutral: all competitors are grey, the producer’s own model is highlighted. GPT-5.4 leads at 58.0; GLM-5.1 sits at 54.9. All seven models fall within a 12.5-point range. Whether that gap matters for your agent depends entirely on what your agent does — and that is exactly what this chart cannot tell you.
A better signal: run the model on your actual task. Not a generic prompt, not a demo — your agent’s specific mission. SiliconSoap uses model debates as a proxy: route two models into a structured debate on a complex topic and observe the quality of their arguments and counter-arguments. It is a better indicator of reasoning depth than any benchmark chart.
In April 2026, Gemma 4 launched with a marketing claim of “50–80% better tool calling.” A developer who benchmarked it against Qwen 2.5 32B on their actual workload found a 4% difference — and Qwen came out ahead on the specific parameter patterns their agent used. The marketing comparison was against Gemma 3, not Qwen. No general benchmark surfaced this. Only running both models on the real task did. (source: Appendix E — Model Evaluation)
The practical method: use OpenRouter as your testbench. One API key, 100+ models, consistent format. Test your actual scenario across several candidates, score them on your criteria, pick a winner. Then — and only then — decide where to run it. Separate the model selection decision from the infrastructure decision. Find what works first.
The Economics of Running Models
The cost equation changes fundamentally for agentic systems:
Traditional chatbot: ~500 tokens per request
Agentic loop: 5,000–20,000 tokens per request
100 daily requests: 50K vs up to 2M tokens/day
Monthly cloud cost: ~$15 vs ~$900 (Claude pricing)At low volume, cloud APIs win on convenience. At high volume or with sensitive data, own infrastructure wins decisively.
The break-even calculation for a $20,000 GPU setup at Claude pricing (~$15/1M input tokens) is roughly 1.3 billion tokens per year. For most teams that is still above their usage — but factor in data privacy, compliance, custom fine-tuning, and the break-even moves closer faster than expected.
Think of it this way: a V12 engine is extraordinary, but it burns fuel whether you need the horsepower or not. Every idle loop, every simple retrieval task, every FAQ response — the V12 runs at cost. A smaller, efficient engine costs a fraction to run. For many of the roads you actually drive, it gets you there just as reliably. The optimization craft is knowing which roads require the V12.
Compliance Is Not Optional
For regulated industries, the model deployment question is not economics. It is mandatory:
- Healthcare (HIPAA): PHI cannot leave your security perimeter. Cloud APIs do not provide the audit trail compliance requires.
- Finance (SOX, GDPR, PCI): Data residency laws mean EU customer data must stay in the EU. Audit trail requirements need logging you cannot get from cloud APIs.
- Legal: Attorney-client privilege requires data control. Cloud API = no defensible position.
- Government: Classified data cannot touch external networks.
For these cases, the answer is self-hosted or a trusted partner. Clawable’s partner autoversio.ai provides managed on-premises GPU inference — your data stays within your security perimeter without requiring you to build the infrastructure yourself.
How to Choose
For any agentic system, work through these questions in order:
- Can the data leave your infrastructure? → If no, self-hosted or trusted partner only.
- Do you need frontier reasoning? → If yes, closed-source cloud.
- How many tokens per day? → High volume shifts the economics toward self-hosted.
- Is latency critical? → Local models are significantly faster for loop-heavy agents.
- Are you regulated? → Self-hosted or trusted partner.
Most systems end up hybrid: a frontier model for complex reasoning, an open-weight model for high-volume or sensitive tasks, local inference for low-latency or private cases.
The tooling for self-hosting is mature. Ollama for prototyping, vLLM for production throughput, SGLang for maximum parallelism, TRT-LLM for NVIDIA hardware. The choice of tool depends on your volume, hardware, and operational capacity — not on the model.
The Optimization Craft
Finding the right model combination for your agent is, today, a manual craft. There is no automated system that reliably evaluates model fitness for a specific agentic task. The agent manager plans for it, chooses, runs tests, monitors outputs, and adjusts.
This will change. Automated model evaluation — agents benchmarking other agents against production tasks, continuous routing adjustments — is coming. But right now, doing this work carefully produces a meaningfully better, cheaper, and more reliable agent. It is one of the more consequential skills an agentic builder can develop.
The process is almost always a trade-off across reasoning depth, cost, speed, privacy, and tool calling quality. The V12 versus the efficient engine. The cloud frontier versus the local workhorse. Getting it right requires running models on real tasks, reading real outputs, and deciding with real data.
What Changes Fast
Model rankings change every few months. The specific models mentioned here will be outdated. But the dimensions — context window, tool support, cost model, license, latency — are stable evaluation criteria regardless of which models are current.
The trust principle does not change: data that cannot leave your infrastructure cannot go through a cloud model. This is a structural constraint, not a temporary gap.
Build your system to be model-agnostic from the start. OpenClaw did this. Flowwink did this. SiliconSoap did this. The pattern is consistent: the model is the engine, the agent is the car. Swap the engine when a better one appears — without rebuilding the car.
Summary
| Question | Answer determines |
|---|---|
| Can data leave? | Cloud vs local |
| Need frontier reasoning? | Closed vs open-weight |
| How many tokens daily? | Cost architecture |
| Is latency critical? | Local deployment |
| Are you regulated? | Partner or on-prem |
| Does it clear the floor? | Minimum denominators |
The model you choose today will not be the best model in 12 months. The question is whether your system is built to swap when that happens — and whether it keeps your data exactly where it needs to be.
Next: you’ve chosen your model — now the question is how your agent talks to it. The API format you pick determines how portable your system is when models change. The API Layer →